Un robots txt bien conçu protège votre budget de crawl, réduit la duplication et sécurise vos zones sensibles.
Ce guide explique comment écrire un fichier robuste, l’adapter à votre architecture (e-commerce, éditorial, multilingue) et mettre en place des contrôles fiables. Objectif : un paramétrage clair, mesurable et durable, sans complexité inutile.
Les fondamentaux : objectifs, syntaxe et priorités
Aligner le contrôle d’accès avec votre stratégie de contenus et votre architecture technique, afin de maximiser l’indexation de vos pages et le budget crawl.
Rôle et périmètre : ce que doit couvrir votre fichier
Le robots.txt est un signal d’orientation pour les crawlers : il indique où autoriser ou restreindre l’exploration. Il ne supprime pas l’indexation d’une URL déjà connue ; pour cela, utilisez des balises meta ou en-têtes HTTP noindex côté page. Sa mission : guider le crawl vers les zones utiles (catégories, contenus piliers), éloigner les filtres, paramètres, résultats de recherche interne et environnements de test.
Gardez une logique simple : d’abord un bloc générique User-agent: *, puis des blocs spécifiques si besoin. Documentez les raisons de chaque règle. Évitez les directives contradictoires et les sur-interdictions qui masquent des problèmes structurels. Le fichier doit vivre avec votre site, pas le figer.
Syntaxe et directives clés (Allow, Disallow, Crawl-delay, Sitemap)
Les bases : User-agent, Disallow, Allow.
Utilisez Allow pour ré-autoriser un sous-chemin utile dans un dossier globalement interdit. Évitez les jokers excessifs : préférez des motifs précis, testés. Crawl-delay peut aider sur des serveurs fragiles, mais n’est pas universellement respecté ; optimisez surtout la performance serveur.
Exposez votre Sitemap via Sitemap: https://www.domaine.com/sitemap.xml. Cela n’ouvre pas l’accès, mais facilite la découverte d’URLs canoniques.
Pensez à l’héritage des règles : une Disallow: /filtres/ bloque aussi /filtres?couleur=, sauf exception ré-autorisée. Testez chaque motif avant déploiement.
Ciblage des user-agents (Googlebot, Bingbot, autres crawlers)
Créez des blocs dédiés pour des bots spécifiques quand vous avez une raison claire : charge serveur, comportement différent, ou obligations internes. Évitez les listes noires interminables : concentrez-vous sur les bots à fort impact et gardez un bloc générique propre. Si vous limitez certains crawlers d’IA, assurez la cohérence avec vos politiques publiques.
Méthodes d’optimisation selon votre site
Adapter les règles au contexte : e-commerce, médias, multilingue, staging.
E-commerce : facettes, filtres et duplication
Bloquez les facettes qui génèrent des combinaisons infinies (/filter/, /sort/, paramètres ?page=, ?tri=) et conservez l’accès aux catégories canoniques. Ré-autorisez les assets utiles (/assets/, /img/) si un dossier parent est bloqué. Évitez d’interdire des pages réellement business (catégories, sous-catégories) : corrigez plutôt la canonisation et le maillage.
Prévoyez un traitement spécifique pour la pagination : interdisez les listings sans valeur (tri, recherche interne), mais laissez crawler les séquences canoniques si elles sont utiles aux utilisateurs. Coupez l’accès aux endpoints d’API privés, zones d’admin et chemins de test produit.
Exemple de robots.txt
User-agent: *
Disallow: /secupress-9806fe28/
# ==========================
# Revue Histoire - Robots.txt optimisé
# ==========================
User-agent: *
# Recherches internes WordPress
Disallow: /?s=
Disallow: /search/
# Filtres WooCommerce & paramètres inutiles
Disallow: /*add-to-cart=*
Disallow: /*replytocom*
Disallow: /*?filter
Disallow: /*~*
# Pages système / admin
Disallow: /wp-login.php
Disallow: /readme.html
Disallow: /wp-admin/
# Dossiers sensibles ou inutiles à l'index
Disallow: /wp-content/uploads/wc-logs/
Disallow: /wp-content/uploads/woocommerce_transient_files/
Disallow: /wp-content/uploads/woocommerce_uploads/
# Flux RSS
Disallow: /feed/
Disallow: */feed
Disallow: /comments/feed
Disallow: /?feed=
Disallow: /wp-feed
# Sitemap principal
Sitemap: https://revue-histoire.fr/sitemaps.xmlSites éditoriaux : archives, tags, recherche interne
Bloquez /search/, /tag/ et /auteur/ si ces pages n’apportent pas de valeur propre et créent des duplications. Gardez l’accès aux dossiers thématiques et guides de référence. Orientez le crawl vers les hubs éditoriaux en évitant les calendriers d’archives jour par jour, souvent pauvres en signal.
Multilingue et multi-domaine : cohérence et héritage
Sur un multilingue, gardez la même philosophie par langue et centralisez vos sitemaps (un par langue si possible). Sur un multi-domaine (ex. .fr, .de), déployez un robots.txt par host et vérifiez que les règles ne brident pas les balises hreflang. Harmonisez les exclusions techniques (fichiers, scripts) pour éviter les divergences.
Contrôle, monitoring et gouvernance
Tester avant, surveiller après, documenter toujours.
Tests, logs et Search Console
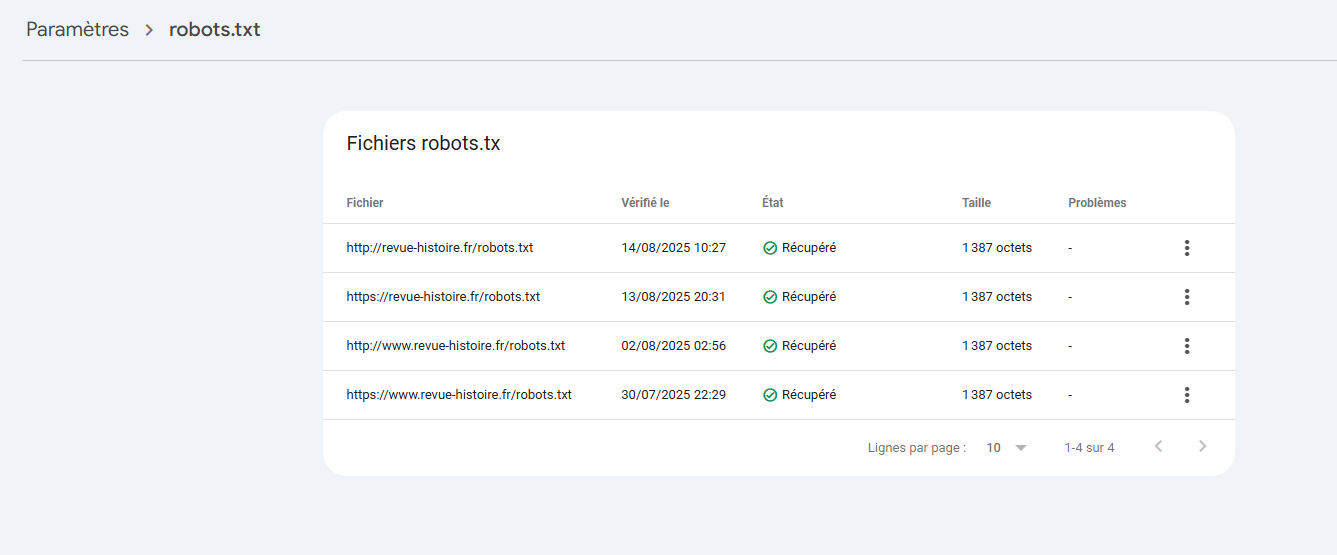
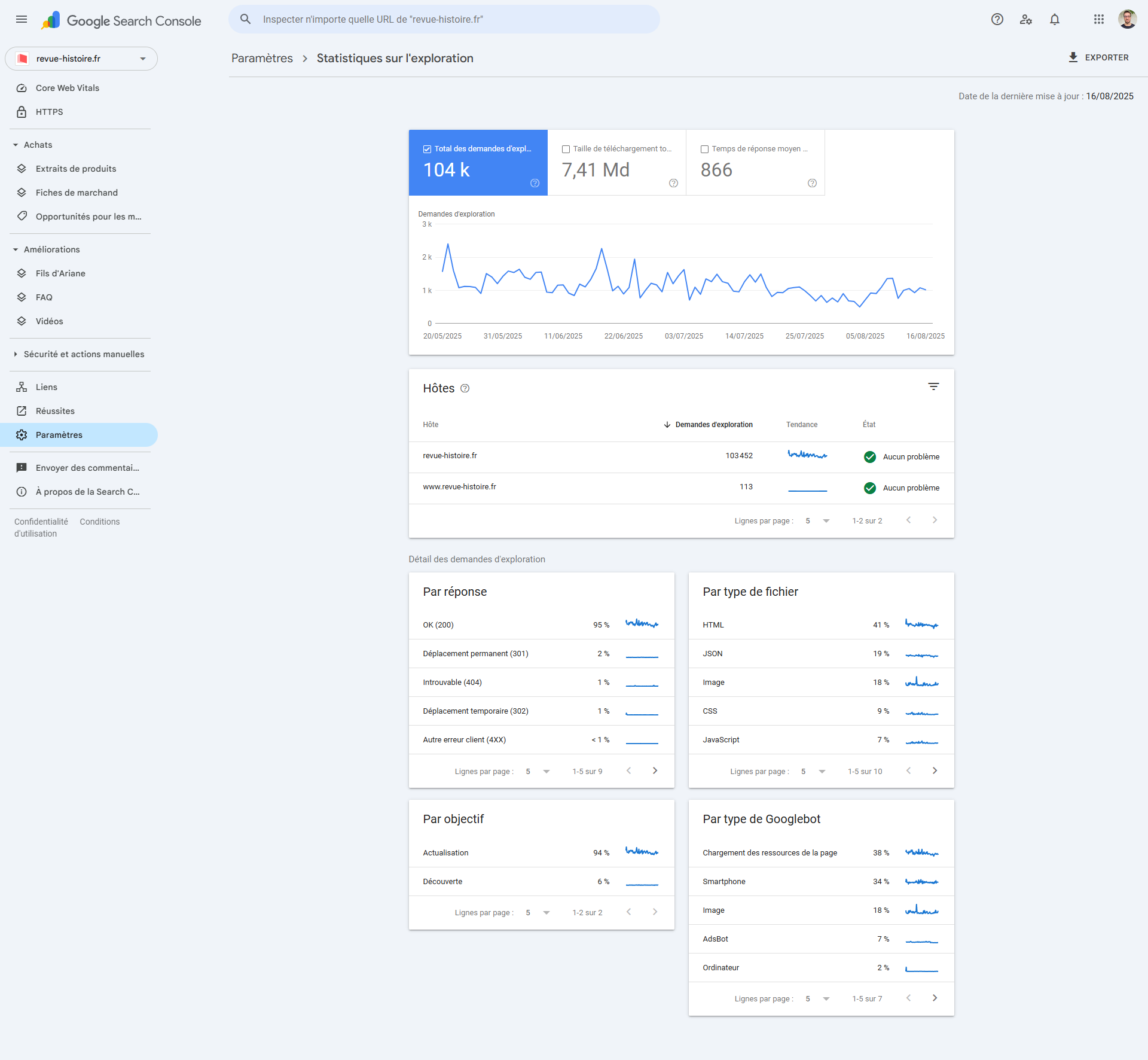
Avant mise en prod, passez le fichier dans un outil de test et validez chaque motif sur un échantillon d’URLs. Après déploiement, suivez les journaux serveurs pour confirmer la baisse du crawl sur les zones interdites et la hausse sur les catégories utiles. En Search Console, surveillez les erreurs d’exploration, l’état d’indexation et la couverture des sitemaps.
Intégrez le robots.txt à votre CI/CD : versionnez, relisez, et forcez une checklist (syntaxe, chemins, sitemaps, commentaires). Documentez les raisons métier de chaque règle pour faciliter les arbitrages futurs.
Sécurité, conformité et collaboration Dev/SEO
N’exposez pas des chemins sensibles : /admin/, /backup/, /scripts/ doivent être protégés serveur (auth, IP), pas seulement “disallowed”. Le robots.txt n’est pas une barrière de sécurité. Organisez une gouvernance conjointe Dev/SEO/Contenu : une règle doit avoir un propriétaire, un objectif et un indicateur de succès.
Les questions qu’on se pose sur robots txt
Le robots.txt empêche-t-il l’indexation ?
Pas à lui seul. Il bloque le crawl, pas forcément l’indexation si l’URL est connue ailleurs. Pour désindexer, utilisez noindex côté page ou retirez les liens internes et sitemaps, puis laissez le temps au recalcul.
Faut-il bloquer toute la pagination ?
Non. Gardez la pagination canonique si elle aide les utilisateurs, mais bloquez les tris/combinaisons sans valeur. Évaluez l’impact sur l’exploration réelle via logs et Search Console.
Peut-on utiliser Crawl-delay ?
Certains bots le respectent, d’autres non. C’est un palliatif temporaire. Préférez optimiser la performance serveur et le cache, et discuter avec l’hébergeur si la charge est anormale.
Où placer le fichier et combien en faut-il ?
Un seul fichier à la racine de chaque host : https://domaine.com/robots.txt. Les sous-domaines ont leur propre fichier. Évitez les redirections complexes qui brouillent l’accès.
Dois-je bloquer les assets (JS, CSS, images) ?
En général, non. Les moteurs ont besoin des ressources pour rendre les pages. Ne bloquez que ce qui est sensible ou inutile, et testez le rendu après chaque modification.
Les points clés à retenir
- Simplicité d’abord : un bloc générique propre, des exceptions justifiées.
- Priorisez les zones business et bloquez facettes, recherche interne, tests.
- Déclarez votre Sitemap et testez chaque motif avant déploiement.
- Surveillez via logs et Search Console ; versionnez et documentez.
- Le robots.txt n’est pas une mesure de sécurité : protégez côté serveur.
Quelques liens et sources utiles
Robotstxt.org












